|
該外掛允許您在儲存網頁的時候,或者使用「批次文章處理」功能的時候,透過自訂的規則,來獲得文章正文,以去除不必要的廣告等其它資訊。
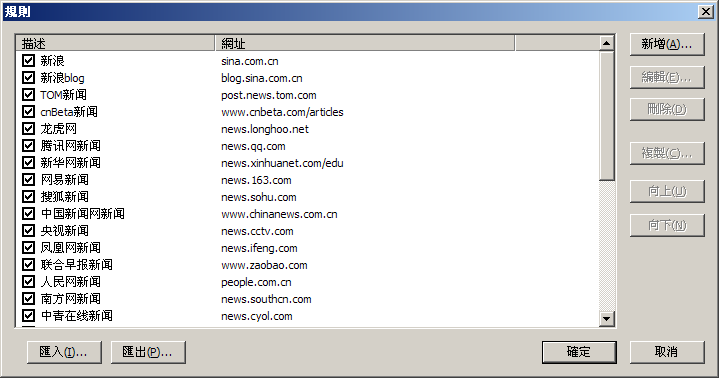
獲得文章正文外掛作用,就是透過自訂的一些規則,來獲得文章正文:下面的對話框,顯示了目前存在的規則。
匯入 按鈕:允許從XML檔案匯入規則。您可以從使用者交流區,獲得其他使用者提供的規則。
匯出 按鈕,允許將目前的規則,儲存成XML檔案,您可以將這個XML檔案,提供給其他使用者使用。
新增 按鈕:允許您自己新增一個規則
編輯 按鈕:允許您編輯已經存在的規則
刪除 按鈕:允許您刪除存在的規則
複製 按鈕:允許您複製一個已經存在的規則
向上 按鈕:向上移動規則
向下 按鈕:向下移動規則
規則:
描述:規則的描述
網址:規則適用的網址。程式會在網頁的原始網址裡面尋找,如果找到規則指定的網址,則使用該規則,否則不使用。如果網址為空,則適用於所有網頁。
尋找正文開始的文字:用來尋找文章HTML正文開始部分的文字標記,例如新浪新聞網頁裡面,文章正文開始,會有「<!--正文內容開始-->」這樣的文字。
正則表示式:尋找正文開始的文字是一個正規表達式。
匹配大小寫:尋找正文開始的文字,需要匹配大小寫。
尋找正文結束的文字:用來尋找文章HTML正文結束部分的文字標記。
新增到正文之前的文字:程式將會把這部分文字,新增到已經獲得的文章正文前面。
裡面可以使用以下參數:
%NodeTitle%:會使用文章標題進行取代。
%NodeURL%:會使用文章來源URL進行取代。
追加到正文之後的文字:程式會把這部分文字,追加到已經獲得的文章正文之後。同樣,程式會取代上面的參數。
包含標記文字:在獲得的文章正文裡面,包含進行標記的文字。
包含HTML頭:最終的文章結果,包含HTML的 HEAD部分。
注意:
在瀏覽器內,選擇「檢視原始碼」功能看到的網頁原始碼,可能和CyberArticle獲得的網頁原始碼有所不同,因此,建議您先儲存一個網頁,然後在CyberArticle裡面檢視儲存後的網頁的原始碼,來尋找合適的文字標記,以取得文章正文。
|